borzov.ca /posts/serene/
serene-audio-mode: how does it work?
Tired of dramatic volume swings in modern movies? Ever got frustrated trying to watch something without disturbing the others? I know I was.
That’s what prompted me to make a thing called serene-audio-mode. It’s an open source tool that rebalances the audio track of videos, selectively reducing the volume of obnoxiously loud, bass-heavy, and jarring sounds (think explosions, gunfire, and aggressive musical beats) while preserving the clarity of other scenes like dialogue.

In this post, we get a bit into the weeds how exactly it works as well as my rationale for this design.
Existing audio rebalancing solutions, like the “night mode” features found in advanced video player applications (VLC, Kodi) or high-end audio amplifiers, typically rely on a family of algorithms called dynamic range compression (DRC).
DRC is a great classic audio algorithm with a long history. Its uses stretch from hearing aids to audio recording hardware. Yet I find that DRC leave things lacking in when it comes to the specific use case of rebalancing we have in mind here.
serene-audio does not use DRC and instead applies its own, and to my knowledge, unique approach.
So let’s break down the process step-by-step.
Step 1: Identifying Loudness Levels of Audio Intervals
The most disruptive sounds we target – explosions, gunfire, crashes, and aggressive music beats, screeching noise and so on – have a characteristically wide frequency profile and narrow time direction span. The wide frequency profile in particular means prominent bass and sub-bass presence.
To illustrate this, let’s examine the “filthy animal” scene from the movie Home Alone (1990). In this scene, we want to identify the audio intervals containing gunfire.
First, we’ll plot the RMS (Root Mean Square) levels, a common metric for loudness, of the scene’s audio track:
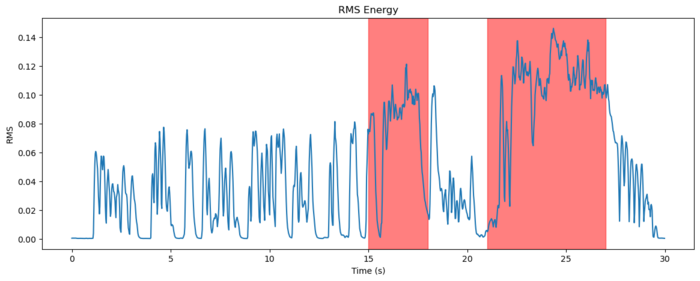
The intervals with gunfire are highlighted in red. While the loudness does peak during these intervals as expected, the difference compared to other spikes is not substantial, only about 25-50% higher.
This relatively small difference in RMS levels doesn’t fully reflect the perceived difference in loudness and obnoxiousness of the gunfire compared to other sounds.
Now, let’s analyze the breakdown of these RMS levels by audio frequency bands:
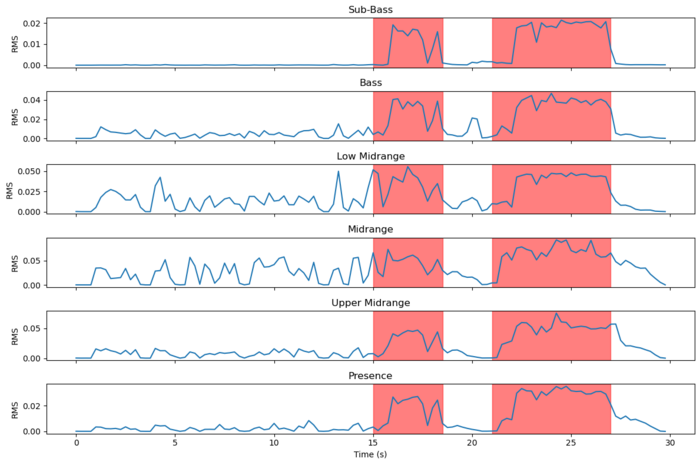
Here, we’re using standard frequency band definitions: Sub-Bass (16 Hz - 60 Hz), Bass (60 Hz - 250 Hz), Low Midrange (250 Hz - 500 Hz), Midrange (500 Hz - 2 kHz), Upper Midrange (2 kHz - 4 kHz), Presence (4 kHz - 20 kHz).
In this breakdown, the gunfire intervals clearly stand out in the sub-bass, bass, and high-pitch frequency bands, outside of the midrange.
As you know, lower pitch sounds are often perceived as the most intrusive. They also travel the furthest. We can often only hear the bass of a song played by a passing car. Therefore, it makes sense to focus on the lowest frequency range as an indicator of the relative loudness and obnoxiousness of an audio interval.
For this reason, when identifying spikes of loudness, serene-audio gives 4x (configurable with BASS_WEIGHT parameter) weight to the impacts at sub-bass frequencies (below 70 Hz).
Step 2: continuous level adjustment
Le’ts say, we determined the level of loudness of a given audiotrack interval to be x. Our loudness readjustment can be described in terms of g(x), the gaian function , that yields the value of the desired level of loudness we would like to readjust the interval to.
Here is the g(x) gain function that serene-audio uses:
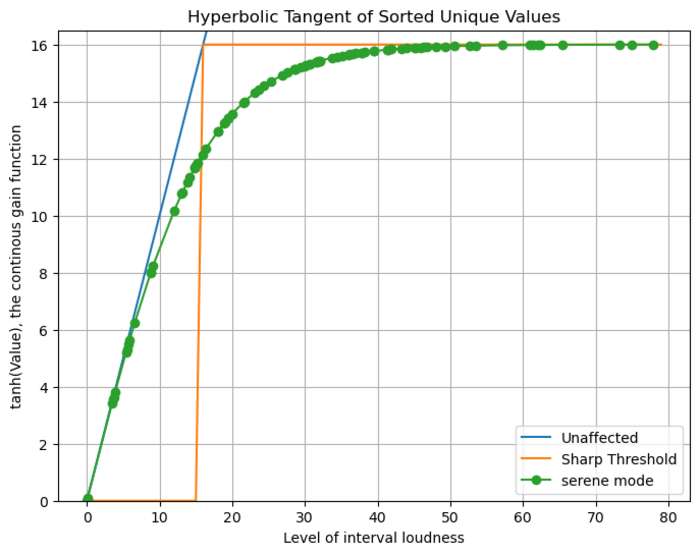
Here on the x axis is the original level of loudness (in the internally used units), and on the y axis we get the desired level (in the same units) to which we would like the interval to be adjusted to.
We see that serene-mode leaves quiet intervals (x < 10) alone, but aggressively caps the levels to the hard threshold y=16.
Importantly, serene-mode avoids a “hard-knee”-style threshold across the full range of its g(x) gain function, where sound attenuation sharply changes around some given value (see orange line on the plot for the facetious example). At it’s worst, such a “hard-knee threshold” may result in audible effect of the attenuation artificially kicking in only beyond certain level.
The mathy way to describe it is that function g(x) is differentiable at every point.
We illustrate application of our g(x) to an audiotrack with this plot of time series of original loudness levels (blue line) vs target adjusted levels (orange line):
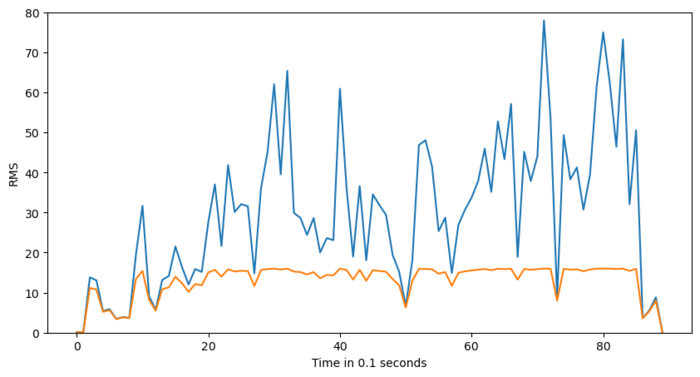
Step 3: smoothing
Sharp adjustments in volume sound unnatural and give off this uncanny feeling.
In serene-mode, the changes of volume to the target levels are applied gradually: spanning to one second by default (can be customized with the time_fade value). This makes these adjustments sound equivalent to someone skillfully reacting with a remote at hand and, I think, sounds much more natural.
The gradual change are log-linear since loudness is perceived at the log scale.
Summary
In summary, here are the features of serene-audio-mode that are missing from dynamic range compression or any other loudness rebalancing solution that I know of:
- It specifically emphasizes the jarring and unpleasant sounds (gunshots, aggressive music beats) by the width of their frequency profile, especially the characteristically prominent bass and sub-bass band contributions.
- No characteristic “hard knee” / threshold kick-in effect. Adjustments are continuously scaled across the entire range.
- Gradual volume adjustments sound natural, indistinguishable from someone manually adjusting the volume with a remote control.